KMP字符串匹配
本文共 2001 字,大约阅读时间需要 6 分钟。
KMP字符串匹配 \operatorname{KMP字符串匹配} KMP字符串匹配
题目链接:
题目
给出两个字符串 s 1 s_1 s1 和 s 2 s_2 s2 ,若 s 1 s_1 s1 的区间 [ l , r ] [l, r] [l,r] 子串与 s 2 s_2 s2 完全相同,则称 s 2 s_2 s2 在 s 1 s_1 s1 中出现了,其出现位置为 l l l 。
现在请你求出 s 2 s_2 s2 在 s 1 s_1 s1 中所有出现的位置。定义一个字符串 s s s 的 border 为 s s s 的一个非 s s s 本身的子串 t t t ,满足 t t t 既是 s s s 的前缀,又是 s s s 的后缀。
对于 s 2 s_2 s2 ,你还需要求出对于其每个前缀 s ′ s' s′ 的最长 border t ′ t' t′ 的长度。输入
第一行为一个字符串,即为 s 1 s_1 s1 。
第二行为一个字符串,即为 s 2 s_2 s2 。输出
首先输出若干行,每行一个整数,按从小到大的顺序输出 s 2 s_2 s2 在 s 1 s_1 s1 中出现的位置。
最后一行输出 ∣ s 2 ∣ |s_2| ∣s2∣ 个整数,第 i i i 个整数表示 s 2 s_2 s2 的长度为 i i i 的前缀的最长 border 长度。样例输入
ABABABCABA
样例输出
130 0 1
样例解释
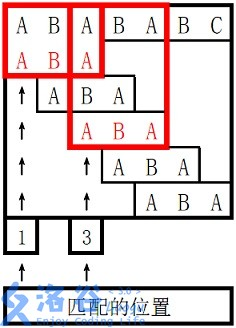
数据范围
Subtask 1 1 1 ( 30 30 30 points): ∣ s 1 ∣ ≤ 15 |s_1| \leq 15 ∣s1∣≤15 , ∣ s 2 ∣ ≤ 5 |s_2| \leq 5 ∣s2∣≤5 。
Subtask 2 2 2 ( 40 40 40 points): ∣ s 1 ∣ ≤ 1 0 4 |s_1| \leq 10^4 ∣s1∣≤104 , ∣ s 2 ∣ ≤ 1 0 2 |s_2| \leq 10^2 ∣s2∣≤102 。 Subtask 3 3 3 ( 30 30 30 points):无特殊约定。 对于全部的测试点,保证 1 ≤ ∣ s 1 ∣ , ∣ s 2 ∣ ≤ 1 0 6 1 \leq |s_1|,|s_2| \leq 10^6 1≤∣s1∣,∣s2∣≤106 , s 1 , s 2 s_1, s_2 s1,s2 中均只含大写英文字母。思路
这道题是一道模板题。
这个KMP的主要思想就是记住你之前匹配时错误的经验。
我们先让 s 2 s_2 s2 和 s 2 s_2 s2 匹配,得出一个数组 p [ j ] p[j] p[j] ,代表的是当匹配到 s 2 s_2 s2 数组的第 j j j 个字母而第 j + 1 j+1 j+1 个字母不能匹配了时,新的 j j j 最大是多少。 然后就让两个字符串匹配,找到能匹配的,输出出来。最后要输出 border ,其实就是我们的 p [ j ] p[j] p[j] 。
那其实就没了。代码
#include#include using namespace std;int asize, bsize, j, p[1000001];char a[1000001], b[1000001];int main() { scanf("%s %s", a + 1, b + 1);//读入 asize = strlen(a + 1);//求出两个字符串的长度 bsize = strlen(b + 1); j = 0; for (int i = 2; i <= bsize; i++) { //s2和s2匹配 while (j && b[i] != b[j + 1]) j = p[j];//匹配不了 if (b[i] == b[j + 1]) j++;//这一个匹配成功 p[i] = j; } j = 0; for (int i = 1; i <= asize; i++) { //s1和s2匹配 while (j && a[i] != b[j + 1]) j = p[j]; if (a[i] == b[j + 1]) j++; if (j == bsize) { printf("%d\n", i - bsize + 1);//匹配的出来 j = p[j]; } } for (int i = 1; i <= bsize; i++) printf("%d ", p[i]);//输出 return 0;}
转载地址:http://vhph.baihongyu.com/
你可能感兴趣的文章
快速学习汇编之 通用寄存器
查看>>
变量覆盖漏洞
查看>>
weblogic之cve-2015-4852
查看>>
Java注释
查看>>
水调歌头·1024
查看>>
对不起
查看>>
C++ 函数重载
查看>>
Nginx简介
查看>>
Nginx的Gzip功能
查看>>
基于.Net Core 5.0 Worker Service 的 Quart 服务
查看>>
Azure Storage 系列(四)在.Net 上使用Table Storage
查看>>
我成为 Microsoft Azure MVP 啦!(ps:不是美国职业篮球)
查看>>
异步编程基础
查看>>
[模板] 带修莫队
查看>>
a instanceof A:判断对象a是否是类A的实例。如果是,返回true;如果不是,返回false
查看>>
abstract关键字的使用
查看>>
算法题:获取一个字符串在另一个字符串中出现的次数
查看>>
算法题:获取两个字符串中的最大相同子串
查看>>
Calendar日历类(抽象类)的使用
查看>>
Asp.Net Core&Jenkins持续交付到Windows Server
查看>>